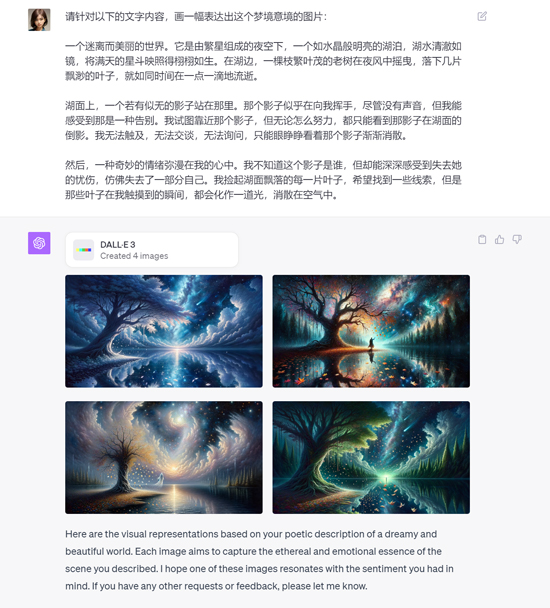
用 DALL•E 3 为《永恒的舞动》创作的插画
这两天用上了 DALL•E 3。
DALL•E 3 描绘出了林浩的工作间,关键词:十平米,落地窗,大书桌。
还让 DALL•E 3 试着描绘出“优雅”的梦境(二雅告别)。
小说《永恒的舞动》 | 评论已关闭 | 3,909 次阅读
简短地址:http://ncblog.net/2089/
今年九月的气候
要么,秋老虎热
要么,“黄梅天”一样老下雨
瞎拍乱照 | 评论已关闭 | 3,952 次阅读
简短地址:http://ncblog.net/2078/
蓝调魔都 vs 血色魔都
瞎拍乱照 | 评论已关闭 | 3,548 次阅读
简短地址:http://ncblog.net/2075/
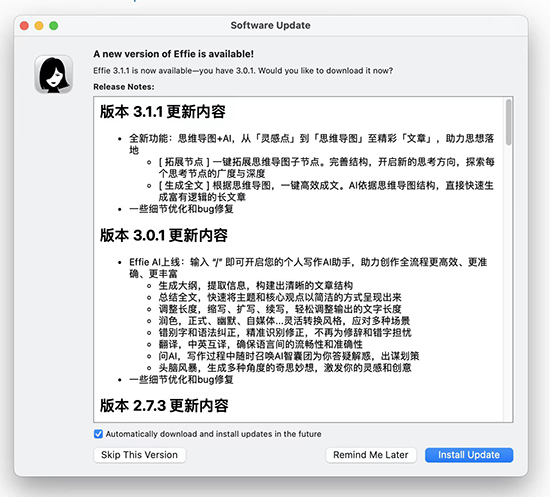
Effie (macOS) AI for 思维导图上线
Effie for macOS v3.1 with Effie AI for 思维导图。
Effie | 评论已关闭 | 3,591 次阅读
简短地址:http://ncblog.net/2067/
写作三个月
从6月10日开始写作小说《永恒的舞动(Elegance in Timelessness)》,已经满三个月。到今天已经写了 8.6万字,也算还保持住了接近“日均千字”的水平吧。
在起点 上,满月不久似乎就停止引流了,估计是检测到在“起点”外(我的个人网站,以及微博上)也有连载?推荐数停留在了25,收藏数停留在了45。
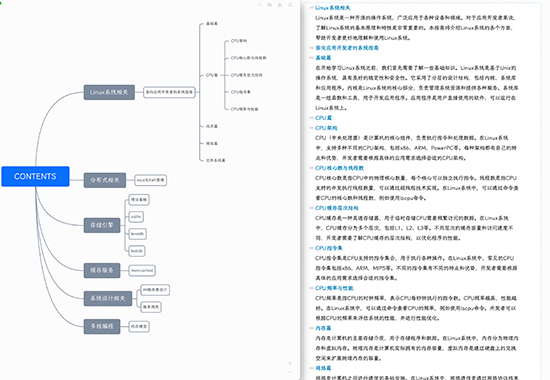
从第二个月起,我多了一个 AI 副驾驶——Claude 2。Claude 2 是目前地球表面对长文理解最好的 AI,没有之一。有很多 AI 模型号称支持长文,8K,16K 或者 32K(token),但常常这只代表能接收的文本长度,而并不代表能够真正理解和处理的长度。另外,有些使用向量数据库来解决文本长度问题的,往往实际效果也差强人意。Claude 2 的实实在在的 200K token 的长度,目前无出其右者。我的小说的前45章大概 7.6万字,对应基本上就是 200K 的 token,喂给 Claude 2 后,询问角色之间的关联,如图:
前天,Claude 2 发邮件通知我可以升级到 Pro 会员了,每月20美元,和 ChatGPT Plus 一样。目前 Pro 会员的权益,大概仅限于用量是免费用户的5倍,未来可能会包括新功能的优先使用等。
我立刻开通了 Claude 2 的 Pro 会员,加上 ChatGPT Plus,双会员。一个月40美元就能实现这个时代的 AI 自由,不得不说是一种幸福。
另外提一句,作为 Effie 的开发者,有了亲自的小说创作经验,我想我大概知道未来的 Effie 以及 Effie AI,应该是什么样的了。
无酒无花 | 评论已关闭 | 3,581 次阅读
简短地址:http://ncblog.net/2060/
Effie AI 上线
Effie for macOS v3 with Effie AI 终于上线了。海外版 在8月初已经上线,国内版 由于监管政策原因,拖了很久,现在终于也上线了。
用 Effie AI 给自己的小说章节做摘要、做翻译,都得心应手。
Effie | 1 个评论 | 7,075 次阅读
简短地址:http://ncblog.net/2054/
网站被黑
上周六下午,刷 https://nicrosoft.net/blog/ 时,突然刷出了 404。SSH 登录上服务器,才发现久未关注的服务器上,WordPress 网站目录下已经遍布了 wpconfig.bak.php 这样的黑客留下的恶意文件。
因为这台服务器上的网站一直运行良好,就很久没有关注过它了。所以,在备份了日志后,当即还是决定彻底重装整个系统。这台机器上主要都是我个人相关的网站,没有什么重要的在线服务,因此也就断断续续花了好几天,才把所有环境都恢复起来了。小说也断更了好几天了。
之后,还在 MySQL 数据库里,发现了黑客添加的几个 WordPress 管理员帐号。
所以,最后决定好好增强一下 WordPress 的安全性。WordPress 自身,以及因为支持各种良莠不齐的插件,安全性一直是被诟病的。之前觉得自己的网站没什么人关注,应该不值得成为黑客目标,当然也是对自身运维方面有一定的信心,尤其是一直稳定运行了超过十年,所以就真的大意了。
亡羊补牢,经过对被黑网站的日志的分析,黑客的行为大致还是有迹可循的。对于 WordPress 架设的网站,我建议:
尽量不安装,或者少安装第三方插件。并不是说,用的人越多,越流行的插件就没问题。流行度越高的插件,被黑客研究利用的可能性也越大。插件开发者水平参差,不见得每个插件都能在安全性上下足功夫。
自己配置 web 服务器,比如 nginx,要禁止在敏感目录(比如 /wp-content/uploads/)执行 php 文件。可以在 nginx 的网站配置中增加类似下面这段:
location /wp-content/uploads/ {
location ~ .*\.(php|php5)?$ {
deny all;
}
}
配置禁掉 /xmlrpc.php:
location = /xmlrpc.php {
return 403;
}
监控网站目录中文件的异常变动,比如增加了什么奇怪的文件。
监控网站的数据库中用户数量的异常变动,比如增加了奇怪的管理员权限的账号。
关于上面第4、第5两点,我准备写一个监控工具定时自动执行来完成。昨天已经在 github 开了新项目:https://github.com/shenmin/wpsec_mon
目前完成了监控数据库中用户数量的异常变动,发现增加了可疑账号时,发送邮件通知。定时执行则借助系统的 cron 服务即可。后续还会继续做下去,把文件监控完成。
农码生涯 | 1 个评论 | 17,399 次阅读
简短地址:http://ncblog.net/2032/
4090 直出 1024×1024 大片
换上 4090,果然出大片几率大增,1024×1024直出(无hires.fix,无upscale)
软硬兼施 | 评论已关闭 | 3,158 次阅读
简短地址:http://ncblog.net/2027/
写作满月
6月10日,周六,我订阅 ChatGPT Plus 的第三天,开始了小说《永恒的舞动(Elegance in Timelessness)》的写作。所以设定了小说中的开始日期,是 2032年的6月10日。
今天7月9日,满月。总共输出了3万字,日均千字,效率算是不错。在起点上获得了 18张推荐票和36次收藏,挺开心的。
我说使用 GPT4 做副驾协助我写小说,有人以为是 GPT4 在写。其实,GPT4 的协助比这些人想象的要弱得多。很多人被现在制造恐慌的舆论风潮影响而产生误解,以为 AI 很快或者已经能够取代人类。就我这一个月的使用心得,我认为,目前的 AI 写不了小说。当然,如果非要抬扛,我不否认它或许存在可能,能写一些千把字的微小说。以我近三十年的代码经验来评估,我同样觉得目前 AI 写不了代码。如果非要抬扛,我不否认它可以帮你输出一些代码示例。就如同千把字的“创作”,我不认为是在正经写小说,代码示例片段,我也不认为是正经的写代码。GPT4 的记忆力甚至不如金鱼,让它主笔写小说,或者是架构一个系统,都是笑话。
AI 目前代替不了人,但是毫无疑问,它能很大程度地提升人的效率。
这一个月,我用 GPT4 做副驾和陪聊,就小说内容,产生很多灵感和启发。昨晚我的 GPT4 模型异常下线时,我也停下了码小说的键盘,无心写作了。我觉得我依赖它,依赖它带给我的效率提升,这和上面的观点也并不矛盾。
另外提一句,昨晚 GPT4 模型异常下线时,ChatGPT 只给我用 3.5 的模型。用惯了 GPT4,回到 3.5 真的很令人嫌弃,哈哈。幸好很快就恢复了。
无酒无花 | 评论已关闭 | 3,545 次阅读
简短地址:http://ncblog.net/2012/
《永恒的舞动(Elegance in Timelessness)》小说封面
用小程序三机器 AI 画出的封面底图,让设计师朋友加了字
三机器 AI | 评论已关闭 | 3,423 次阅读
简短地址:http://ncblog.net/2002/